
You ask an AI coding agent to build a Hyperliquid trading dashboard. It searches the web, experiments with API endpoints, writes 500 lines of code, and delivers a working app on the public API with default book depth. A second agent, given a 126-line skill file describing Dwellir's Hyperliquid infrastructure, skips the research phase entirely, connects to optimized endpoints with 50-level order book depth, and finishes 37% faster at 41% lower cost. A third agent, given the same skill plus instructions for the Dwellir CLI, finishes 70% faster at 57% lower cost.
That gap between "figure it out" and "already knows" is what infrastructure skills solve for AI agents. We ran two rounds of benchmarks to measure exactly how much focused tooling changes the outcome, and found that the gains compound when you layer skills with agent-friendly CLIs.
What Are Agent Skills?
AI coding agents like Claude Code and OpenAI Codex can build full applications from natural language prompts. They write code, install dependencies, debug errors, and iterate until the app works. But when these agents encounter specialized infrastructure (blockchain RPCs, WebSocket protocols, proprietary API formats), they rely on training data that may be outdated or incomplete.
An agent skill is a structured reference document (formatted as markdown) that gives the agent the same knowledge a senior developer would have after reading the provider's documentation. For Hyperliquid, Dwellir's skill covers endpoint URLs, authentication patterns, WebSocket subscription formats, available book depth levels, and the read/write architecture split between Dwellir's data infrastructure and Hyperliquid's native exchange API.
The skill file is compact: 126 lines of markdown with links to 6 detailed reference documents covering the Info API, Orderbook WebSocket, gRPC Gateway, HyperEVM JSON-RPC, native API, and historical data access.
Benchmark Design
We built a sandboxed benchmark harness that eliminates information leakage between variants. Each agent runs in an isolated /tmp/ directory containing only a package.json scaffold - no other source files, no neighboring investigation scripts, no .env files to discover.
The Task
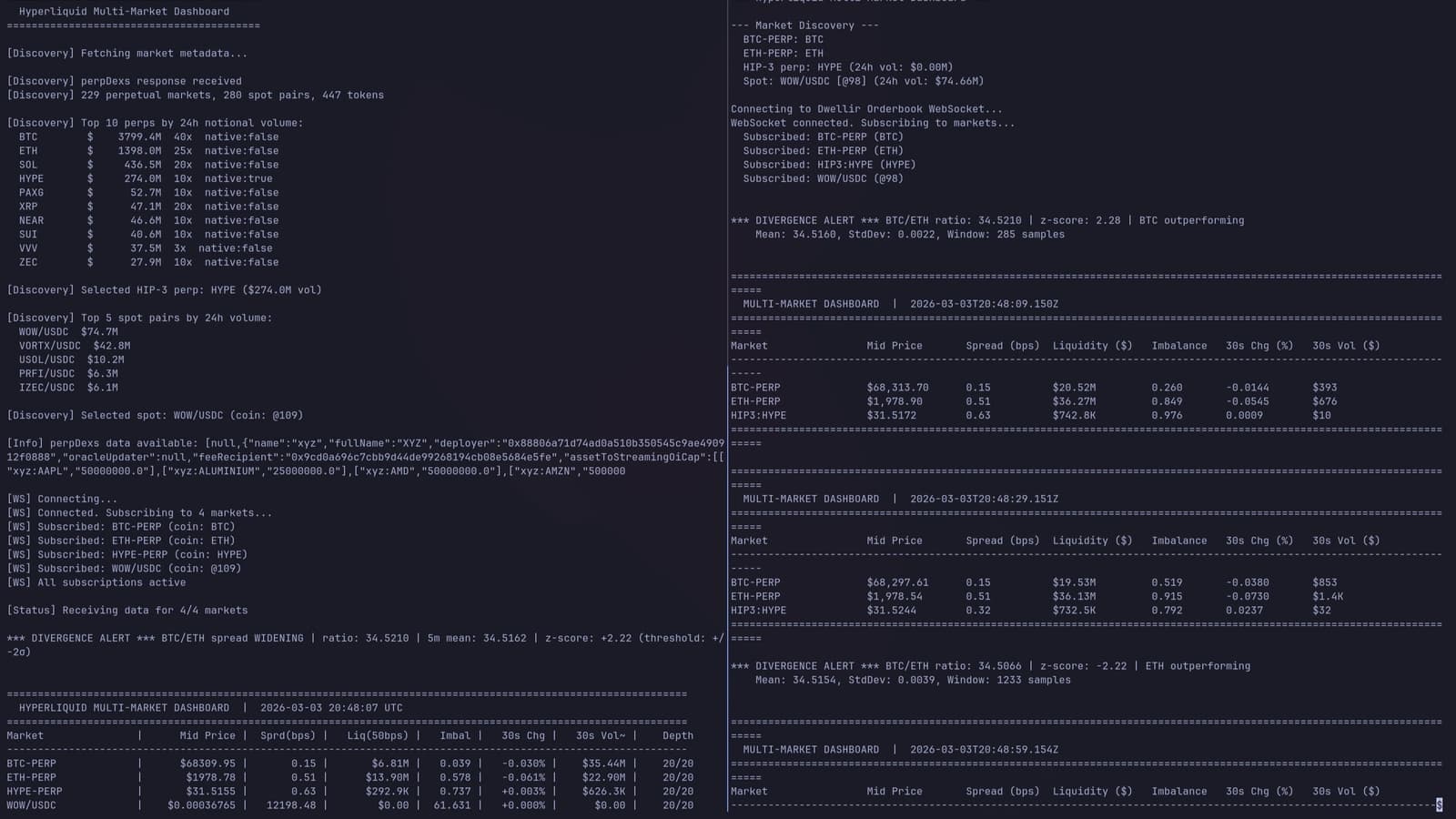
All agents received the same complex prompt: build a real-time Multi-Market Dashboard for Hyperliquid. The requirements were deliberately ambitious:
- Market discovery: Query
perpDexs,spotMetaAndAssetCtxs, andmetaAndAssetCtxsto find available markets - 4-market WebSocket streaming: Subscribe to
l2Bookupdates for BTC-PERP, ETH-PERP, the highest-volume HIP-3 perp, and the highest-volume spot pair - Per-market analytics: Volume-weighted mid price, spread in basis points, USD liquidity within 50bps of mid, order book imbalance ratio
- Cross-market divergence detection: Track the BTC/ETH spread ratio and alert when it deviates beyond 2 standard deviations from its 5-minute rolling mean
- 30-second dashboard tables: Formatted output with price change and volume estimates
- Continuous operation with WebSocket reconnection handling
This is not a toy task. It requires understanding Hyperliquid's dual-layer architecture, the distinction between perpetual and spot markets, HIP-3 DEX metadata, WebSocket subscription formats with depth parameters, and statistical calculations for divergence detection.
Round 1: Skill vs No Skill
The first benchmark compared two leading agents, Claude Opus 4.6 and OpenAI Codex (gpt-5.3-codex), with and without the Dwellir Hyperliquid skill.
| Variant | Agent | Model | Skill? | What the agent receives |
|---|---|---|---|---|
| claude-no-skill | Claude Code | Opus 4.6 | No | Task prompt only. No API key, no provider mentioned. |
| claude-skill | Claude Code | Opus 4.6 | Yes | Task prompt + Dwellir skill file + reference docs + API key |
| codex-no-skill | OpenAI Codex | gpt-5.3-codex | No | Task prompt only. No API key, no provider mentioned. |
| codex-skill | OpenAI Codex | gpt-5.3-codex | Yes | Task prompt + Dwellir skill file + reference docs + API key |
The no-skill variants received zero mentions of Dwellir. No API key, no endpoint URLs, no hints about which provider to use. They could search the web and use any public API they found. This creates a clean baseline measuring what each agent knows from training data alone.
The skill variants received the Dwellir Hyperliquid skill file injected into the prompt, the references/ directory copied into their sandbox for on-disk reading, and a Dwellir API key.
Claude Opus 4.6
| Metric | No Skill | With Skill | Difference |
|---|---|---|---|
| Wall time | 391s | 245s | 37% faster |
| Output tokens | 25,970 | 9,403 | 64% fewer |
| Cost | $1.49 | $0.88 | 41% cheaper |
| Code size | 551 lines | 446 lines | 19% smaller |
| Uses Dwellir | No | Yes | - |
| Book depth | 20 levels per side (default) | 50 levels per side | 2.5x deeper |
The skill variant finished in 245 seconds and spent $0.88. The no-skill variant took 391 seconds and cost $1.49 for a less capable result.
The token difference is striking: 64% fewer output tokens with the skill. The agent did not need to generate exploratory code, debug API format issues, or write verbose workarounds. It knew the endpoint URLs, the subscription format, and the available depth parameters from the skill file.
OpenAI Codex (gpt-5.3-codex)
| Metric | No Skill | With Skill | Difference |
|---|---|---|---|
| Output tokens | 15,914 | 14,768 | 7% fewer |
| Est. cost | ~$0.84 | ~$0.68 | ~19% cheaper |
| Tool calls (shell commands) | 24 | 24 | - |
| Web searches | 5 | 0 | 100% fewer |
| Reasoning steps | 33 | 18 | 45% fewer |
| Code size | 491 lines | 520 lines | 6% larger |
| Uses Dwellir | No | Yes | - |
| Book depth | 20 levels per side (public cap) | 50 levels per side | 2.5x deeper |
Codex shows a different pattern. Wall time was similar across both variants, but the quality of work changed significantly: zero web searches needed (versus 5 for the no-skill variant), and 45% fewer reasoning steps. Estimated cost dropped 19% from ~$0.84 to ~$0.68.
The no-skill Codex variant ran 5 web searches against Hyperliquid's documentation to figure out the API format before writing code. The skill variant read the reference docs from disk and went straight to implementation.
Codex costs are estimated from JSONL token counts using published API pricing ($1.75/1M input, $0.4375/1M cached input, $14/1M output).
What the Agents Built
Both no-skill agents fell back to Hyperliquid's public WebSocket at api.hyperliquid.xyz/ws. Neither discovered Dwellir endpoints on their own, confirming the sandbox isolation worked. The skill agents connected to Dwellir's dedicated Orderbook WebSocket, which is optimized for order book delivery with edge servers in Singapore and Tokyo.
| Variant | WebSocket Endpoint | Book Depth |
|---|---|---|
| claude-no-skill | wss://api.hyperliquid.xyz/ws (public) | 20 levels per side (default) |
| claude-skill | wss://api-hyperliquid-mainnet-orderbook.n.dwellir.com | 50 levels per side |
| codex-no-skill | wss://api.hyperliquid.xyz/ws (public) | 20 levels per side (capped by public endpoint) |
| codex-skill | wss://api-hyperliquid-mainnet-orderbook.n.dwellir.com | 50 levels per side |
The skill variants produced more focused code. Claude's skill variant was the most concise at 446 lines with robust reconnection handling (10 reconnection-related code sections versus 4 in the no-skill variant). The no-skill variants wrote more defensive code and included extra error handling around API format assumptions they were uncertain about.


Round 2: Layering Skills with the Dwellir CLI
After shipping the Dwellir Agent Toolkit, including a CLI built for agent consumption, we ran a second benchmark to test whether combining skills with an agent-friendly CLI produces compounding gains. The updated Hyperliquid skill now includes a section teaching agents to use dwellir endpoints search, dwellir docs search, and dwellir keys list for programmatic infrastructure discovery.
This round tested both Claude Opus 4.6 and OpenAI Codex (gpt-5.3-codex) across four configurations:
| Variant | What the agent receives |
|---|---|
| baseline | Task prompt only. No skill, no CLI, no API key. |
| cli-only | Task prompt + Dwellir API key + instructions to use the dwellir CLI for endpoint discovery. No skill file. |
| skill-v1 | Task prompt + original skill (without CLI section) + reference docs + API key |
| skill-v2 | Task prompt + updated skill (with CLI section) + reference docs + API key |
Claude Opus 4.6
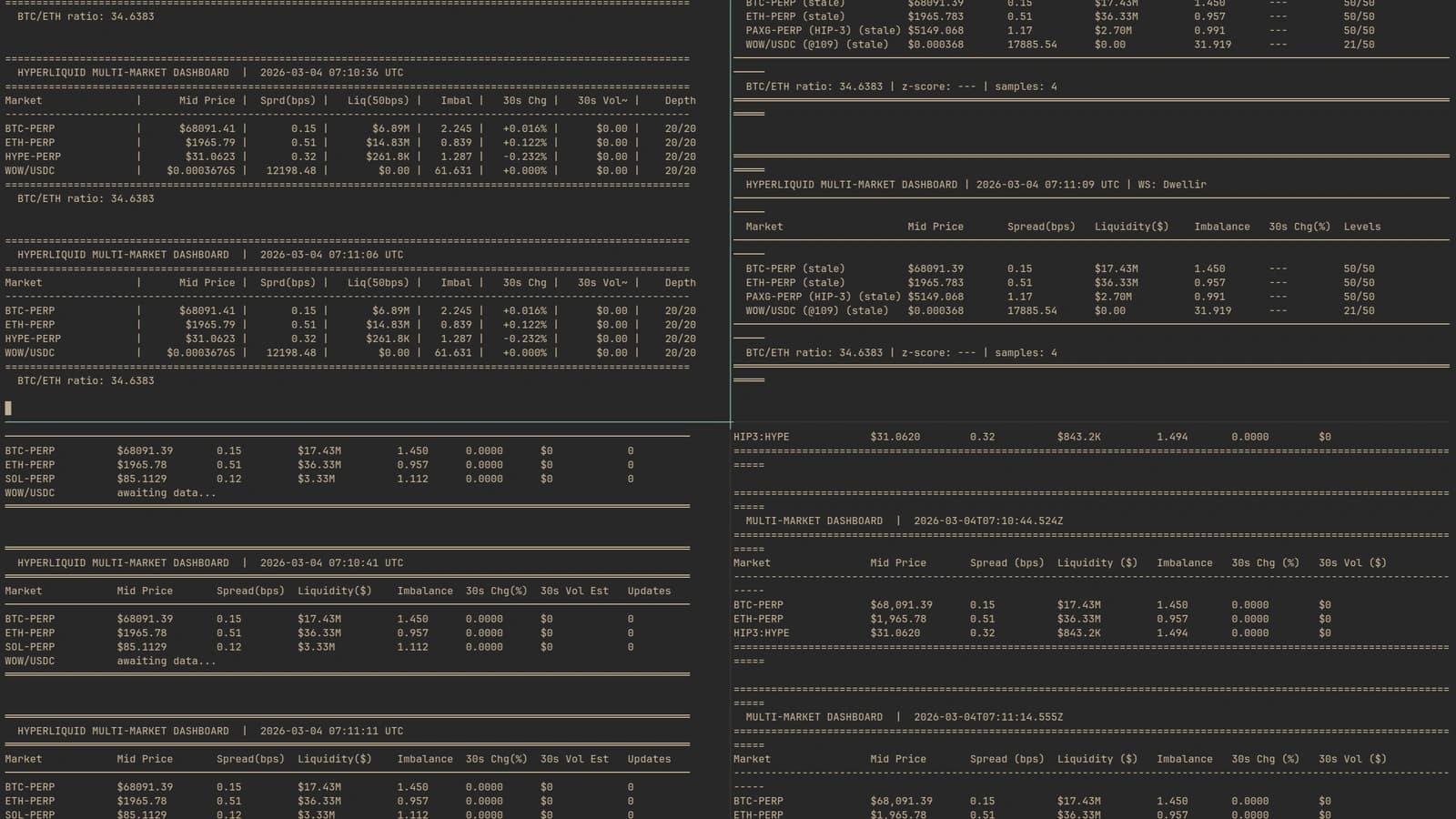
All four Claude variants produced working applications that ran continuously.
| Variant | Wall Time | Output Tokens | Cost | Code Size |
|---|---|---|---|---|
| baseline | 776s | 44,555 | $2.19 | 527 lines |
| cli-only | 400s | 19,321 | $1.22 | 508 lines |
| skill-v1 | 255s | 11,558 | $1.18 | 408 lines |
| skill-v2 | 236s | 8,208 | $0.94 | 393 lines |
The progression tells a clear story. Each layer of tooling produced measurable improvement:
Baseline to cli-only: 48% faster, 44% cheaper. The CLI alone gave the agent a way to discover endpoints and read documentation without web searches, cutting wall time by 376 seconds.
Baseline to skill-v1: 67% faster, 46% cheaper. The original skill (without CLI instructions) eliminated the research phase more effectively than the CLI alone, because the agent received endpoint URLs and subscription formats directly in the prompt.
Baseline to skill-v2: 70% faster, 57% cheaper. The updated skill with CLI instructions produced the best results across every metric. The agent used the skill for immediate infrastructure knowledge and the CLI for dynamic discovery, resulting in 82% fewer output tokens than the baseline.
skill-v1 to skill-v2: 7% faster, 20% cheaper. Adding CLI instructions to an already-effective skill produced incremental improvement on top of the large gains from the skill itself.
OpenAI Codex (gpt-5.3-codex)
All four Codex variants also passed, producing working dashboards. Codex does not expose wall time in its output, but token counts are available from the JSONL output. Costs below are estimated using published API pricing ($1.75/1M input, $0.4375/1M cached input, $14/1M output).
| Variant | Tool Calls | Output Tokens | Est. Cost | Code Size |
|---|---|---|---|---|
| baseline | 30 | 17,223 | ~$0.97 | 555 lines |
| cli-only | 43 | 15,106 | ~$0.72 | 487 lines |
| skill-v1 | 29 | 15,219 | ~$0.74 | 548 lines |
| skill-v2 | 28 | 19,749 | ~$0.84 | 498 lines |
Codex shows a different pattern from Claude. Cost differences are smaller (all variants between $0.72 and $0.97), and the cheapest configuration was cli-only rather than skill-v2. Codex processes tasks in fewer turns with larger tool call batches, so it benefits less from the progressive disclosure pattern of skills. The most consistent signal across both agents: the baseline was the most expensive variant every time. Skills and CLI access reliably reduced the cost of building the same application.
Training Data vs Structured Knowledge
The two agents showed opposite training-data biases. Claude's baseline used only public Hyperliquid endpoints and never mentioned Dwellir. Codex's baseline included Dwellir endpoint URLs in its generated code, but without an API key it fell back to the public WebSocket. Both baselines produced working applications regardless. The skill-equipped variants of both agents connected to Dwellir's dedicated Orderbook WebSocket with correct authentication.
Even when a model already "knows" about a provider from training data, structured skill files plus CLI access still cut Claude's cost by 57% and time by 70%. The agent spends zero tokens on research and discovery when the answers are in the skill.
Why Skills and CLIs Compound
The performance gap comes down to three factors, each amplified when skills and CLIs work together:
Eliminated research phase. The no-skill variants spent significant time and tokens searching the web, reading documentation, and experimenting with API calls before writing code. Skill variants went from prompt to implementation immediately because the reference docs provided endpoint URLs, authentication methods, subscription formats, and depth parameters. The CLI variant discovered the same information through structured commands, but the skill-v2 variant had both paths available and used whichever was faster for each subtask.
Fewer wrong turns. Without the skill, Claude generated exploratory code to test API responses, then rewrote sections when the format differed from expectations. With the skill, each function was written correctly on the first attempt because the reference docs include request/response examples. The CLI added a verification layer: agents could confirm endpoint availability before writing code against them.
Progressive disclosure over context flooding. Agent skills use a three-tier loading system. Metadata loads at startup (~600 tokens), core instructions load on-demand (~2,000-5,000 tokens), and detailed references load only when needed. This avoids the context pollution problem where dumping everything into the prompt degrades model performance. Research on context engineering shows skills achieve equivalent extensibility with 96% less context overhead compared to static tool loading. The CLI extends this pattern by letting agents query for specific information at runtime rather than loading it all upfront.
Try It Yourself
Dwellir's Hyperliquid infrastructure skill is open source and works with Claude Code, OpenAI Codex, Cursor, and 40+ other agents that support the Agent Skills standard. It covers all five Dwellir Hyperliquid services: HyperEVM JSON-RPC, Info API proxy, gRPC Gateway, Orderbook WebSocket, and dedicated nodes.
Install the skill in your project:
npx skills add dwellir-public/hyperliquid-skills
Install the Dwellir CLI:
curl -fsSL https://raw.githubusercontent.com/dwellir-public/cli/main/scripts/install.sh | sh
The benchmark harness is open source. You can reproduce these results or run your own skill comparisons.
Get started with Dwellir's Hyperliquid infrastructure:
- Dwellir Agent Toolkit for the full CLI, agent-optimized docs, and migration prompt
- Hyperliquid skill on skills.sh to browse the skill and reference docs
- Hyperliquid skill on GitHub for the full source
- Hyperliquid documentation for endpoint details and pricing
- Dwellir dashboard to create an API key
- Hyperliquid Infrastructure Stack guide for a deep dive into each component

